Outside of programming, one of my biggest passion’s is playing Boardgames. What better way than to combine the two? In this two part series I want to digitalize of the fun boardgames that I enjoy, namely Cat In The Box. Now, over time I want to be able to create a website where you can play this game with friends online. However to add to that, I also wanted to play around with some RL and create an AI that could play this game as well. In this post, I talk about my experiments creating an AI that can play Cat In The Box well, by training it only using RL!
Overview
Cat in the Box, designed by Muneyuki Yokouchi, is a fun trick taking game that emulates the concept of Schrodinger’s cat - unless you actually look in the box you do not know whether it is alive or dead. This game twists the concept giving you only numbered cards, and then making you choose the suit(red, blue, yellow or green) only when it is played. If you want to follow the specific rules, you can find them over here.

In this project, I’ll be focusing directly on the 4 player version as it fixes the setup and makes learning a bit easier. The 40 cards (5 copies of the numbers 1-8) are randomly distributed among the 4 players. Each player then chooses and discards one of their cards, as well as makes a bet as to the number of sets they think they might win. Finally they play up to 8 ‘sets’ where they play cards.
In this project, I want to train an agent to be able to play the entire game, including discarding cards, setting their bet and playing the sets.
Note: This game is not truly deterministic. Unlike Chess, Go, Pong, etc. at a given point playing a particular move will not always lead to the same next state and is dependent on card distribution as well as other player actions. This adds some challenges and affects the best possible model that can be achieved.
Code Repository:
All the code for this project can be found in my github repository.
Reinforcement Learning Overview - A short dive
Reinforcement learning is different from normal Deep Learning due to the fact that there is no fixed data set. Instead there is a way for the training to actual go through the different actions and dynamically generate new data to train on. Each time an action is taken, a new state and reward is given. The model then
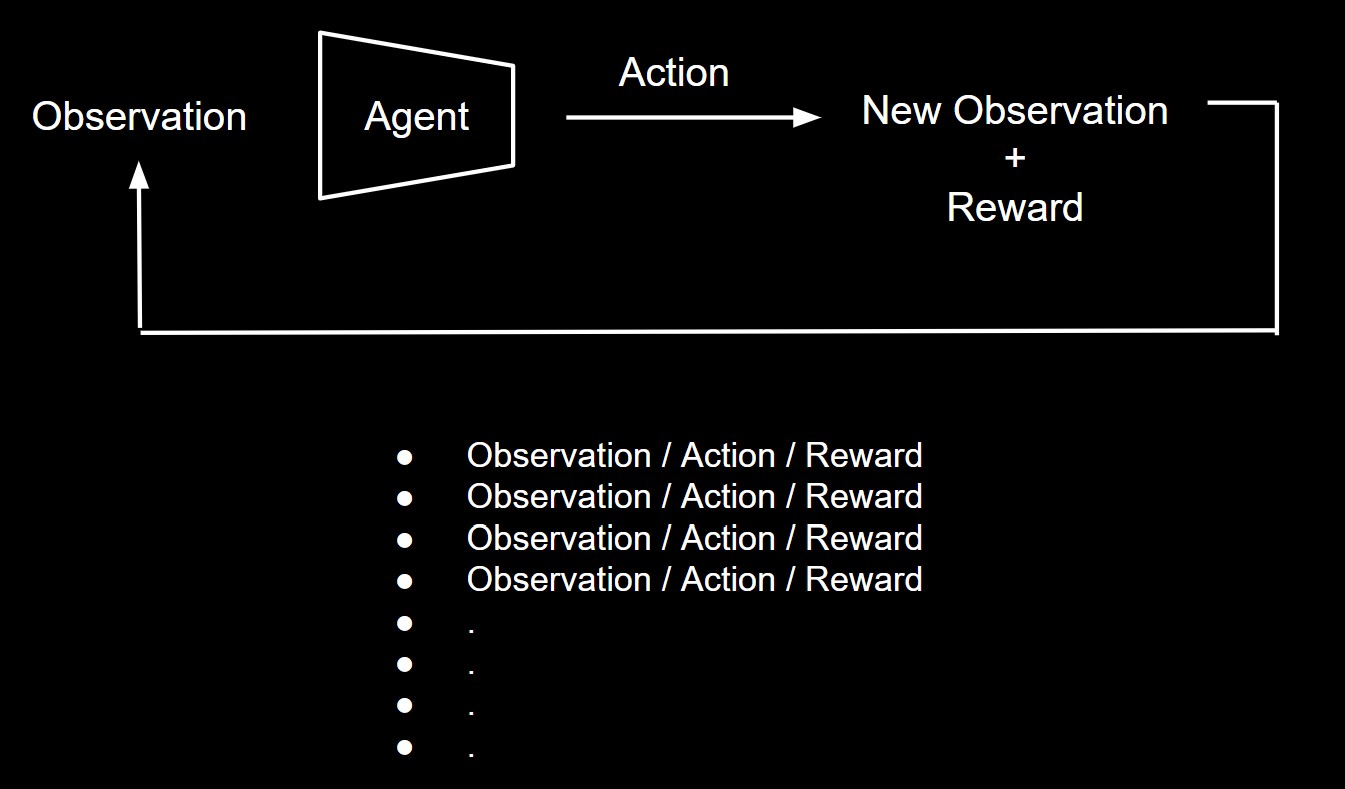
The agent model is an ML model that given an observation, estimates the expected reward when taking different actions. By going through multiple (thousands/millions) observations / actions / rewards, an agent (ML model) is taught to learn which actions are beneficial and which are not as much. The agent can thus decide what the best action to take by checking the predicted rewards and maximizing the expected reward.
Project Setup
Packages
For the training I used stable-baselines3 along with gymnasium environments. Stable-baselines along with gymnasium give a very good way to not only collect different training rollouts, but provide the implementation of a large number of RL models to use out of the box. Behind the scenes these models use pytorch to setup and train the model, and logs progress and statistics using tensorboard. Instead of Tensorboard, I used WandB, which has an inbuilt integration with stable baslines, to collect, visualize and analyse the results.
Gymnasium
I built my own Custom Environment on top of Gymnasium’s base environment. To define the environment we first need an action space and an observation space.
Action Space:

As far as I see there are three distinct actions that a player can make:
- Discard a card: At the start of the game, players are required to discard one of their 10 starting cards. Given there are 8 numbers, a player can discard one of 8 different cards.
- Set a bet: The players also have to make a bet of how many sets they think they are going to win. Either 1,2 or 3 in a 4 player game.
- Play a card on the board: This is the meat of the game. Players play a card from their hand, stating a color and placing their tile on the corresponding space on the game board. Eg: Play a 8, say the color is Blue and cover the Blue 8 spot on the board.
Overall that gives 43 different actions that the model can make. 8 can only be done in the first turn of the game, 3 in the second turn and the remaining 32 actions after that.
Observation Space:
Since the game is made fixed actions and numbers, I could use a multi discrete action space. I thought about this from a player who is playing the game’s perpective. What information a player would have is what I would pass in to the agent as well.
This includes the cards in the hand, cards played the board state and visible information of other players. In addition I added a turn number, as well as a one hot encoded ‘phase’ variable (100 for discard, 010 for bets and 001 for play cards) which could help with choosing actions for different phases.

The total gives a list of size 81 for the observation space (can check the code for full details). Stablebaselines also performs an optimization to convert each discrete value into one hot encoding vectors. Therefore a variable i, whose value can range from 0-10 is converted to a one hot encoded vector of size 11 before being sent to the model. Hence the final input to the model is of size 194.
Custom Environment:
The Stable Baselines Guide for using a custom environment is what I used to build environment. In short, in order to create your own environment, you need to implement 3 main features:
- Initialization: Here you have to set the action and observation space using gymnasium spaces. As mentioned above, since all my actions and observations were fixed values, I could use Discrete valued spaces.
- Reset: In this function, the environment needs to be reset back to it's original state / starting state along with the initial observation. In my case, it was resetting the game and redistributing a new set of cards.
- Step: This is what needs to needs to happend to the environment when the agent takes an action. Based on what action is taken, the board state should be updated, and the new observation space, along with the reward as well as if the end status should be returned. Initially I set the reward to 0 for all actions except when the game was over (where the actual score was resturned). If any invalid action was played I returned a high negative value to stop the action from being taken.
In my code, the environment is set up as the class CitbEnv, backed by a RoundEnv that contains the board, the other players and functions to represent the different actions and corresponding board updates.
Model
For the model, I used the DQN (Deep Q Network) that uses an MLP to learn the underlying Q function. Behind the scenes, Stable Baseline’s implementation of DQN uses a replay buffer, that stores the different rollouts and retrains on a subset of the replay buffer at continous timesteps.
Training
Initial Training
Having set up the environment, written some logic for the sample bots, and set up the training pipeline, it was time to start training. Since a decent chunk of RL training is collecting the rollouts, training this on a GPU did not help and hence I mostly trained the model on my laptop as compared to a Colab Notebook or a cloud server with a GPU.
The reward system I had used was:
- Discard phase (1st action): 0 if valid card in hand. -100 if invalid card or non discard action.
- Bet Phase: 0 if bet 1,2 or 3 action was chosen, -80 otherwise.
- Play Cards Phase: -60 if discard or bet action chosen. 0 if valid move played. And -40 if invalid move played (Eg playing Blue 8 when not having an 8 card in hand) + 2 * turn number (-40 if first card played was invalid, -38 if first card played valid and second invalid, etc.) in order to give it some direction.
While the model was able to predict actions and the pipeline worked, the model was unfortunately….. terrible. I tried training the model from scratch for 400k - 1mil steps, as well as reloading a previously trained model and continuing the training for a second or third time. The model still performed badly, not being able to even get close to finishing the game.
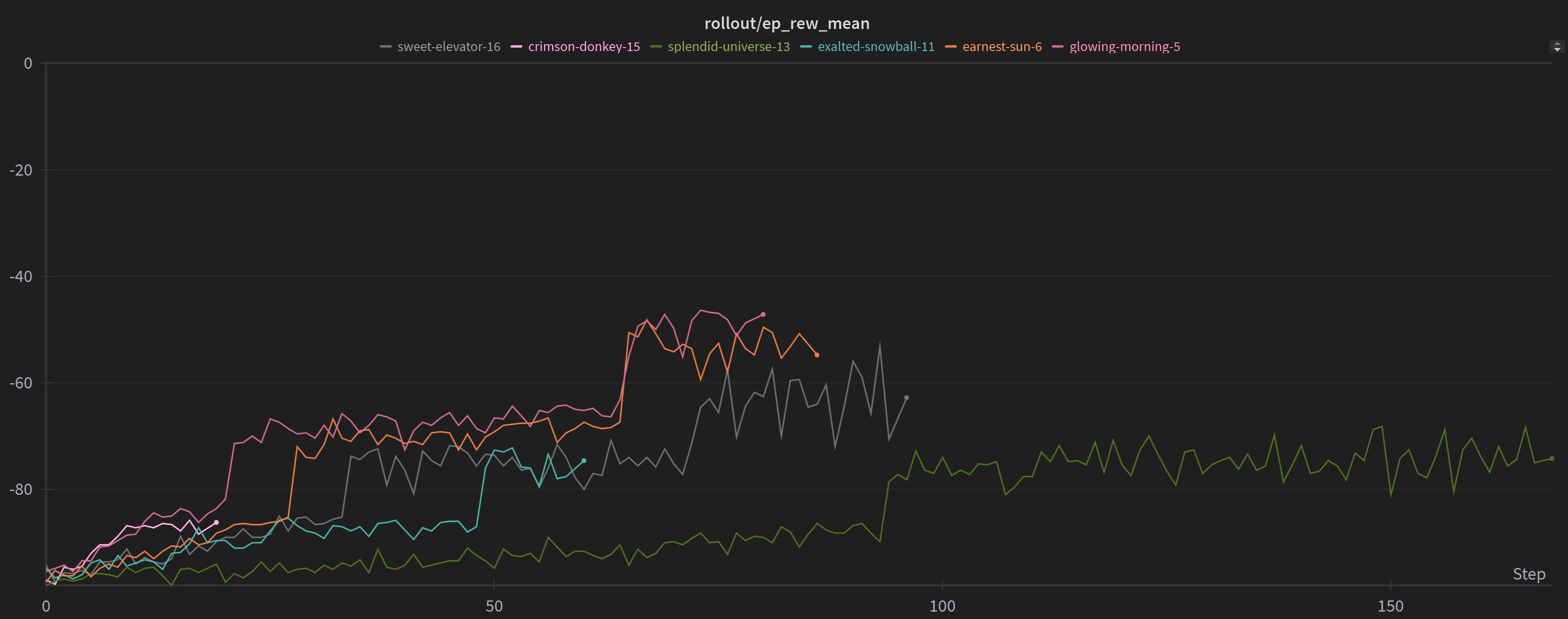
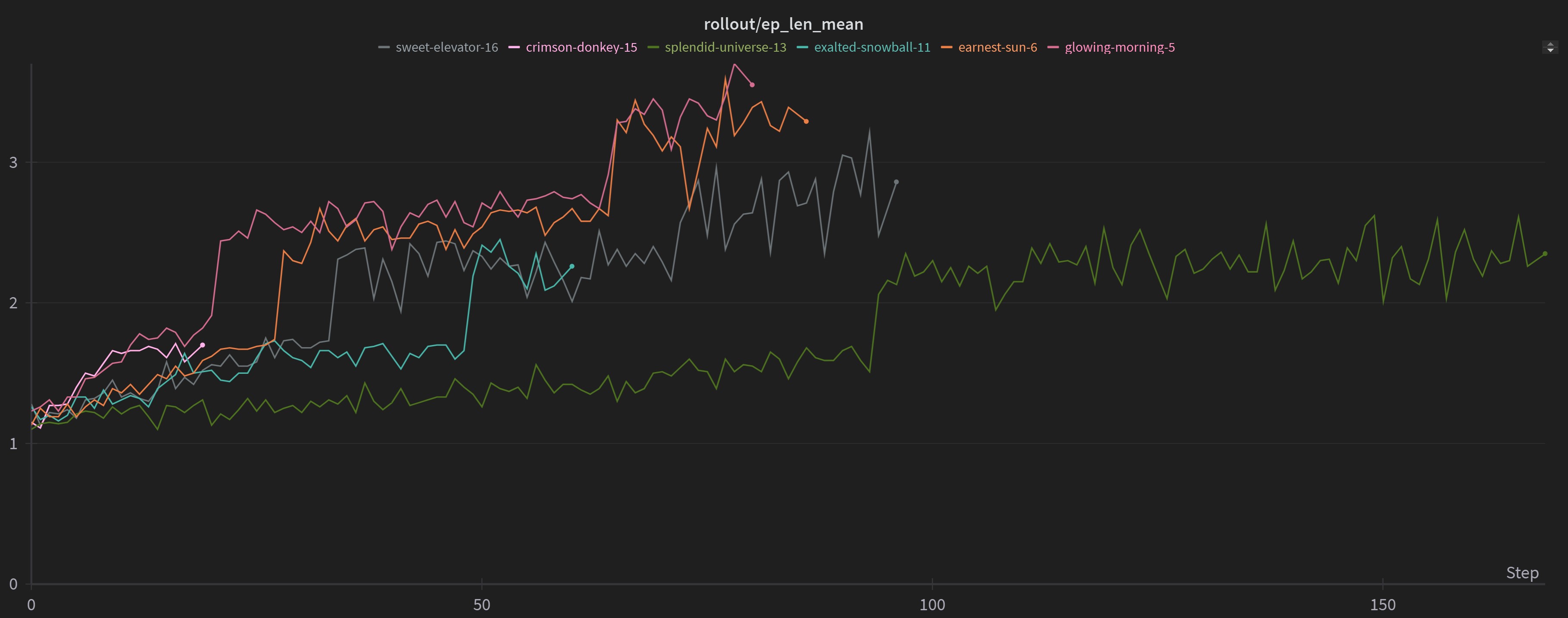
The model seemed to be hitting a wall everytime it reached a new step. To give context, the model had to take nearly 100,000 actions playing the game before learning that only the first 8 actions (out of 43) were valid to play in the first step.
The next step had only 3 valid actions (bet 1, 2 or 3).
However the third step had 32 different actions that could be played and whose validitiy varied widely on the board state as well as the cards in hard, and this set of valid moves would keep reducing as more and more cards were played. As long as the model kept playing invalid moves, it only kept getting a negative reward. As a result it just needed to keep trying and failing and trying and failing before it could progress.
While I think it may have been possible for the model to maybe learn over tens of millions (multiple days of training), I did not have the patience to let it run on my laptop and test the hyposthesis.
It was time for plan B.
Masking
Instead of letting the model learn from scratch, I decided to interfere and teach the model a bit of the rules. I did this by masking the invalid actions - meaning when predicting the next action to take, the model would only be able to choose from any of the valid actions.
What are the invalid actions? For example, taking a discard action when a card needs to be played, or discarding a 2 at the start when there are no 2s in the agent’s hand.
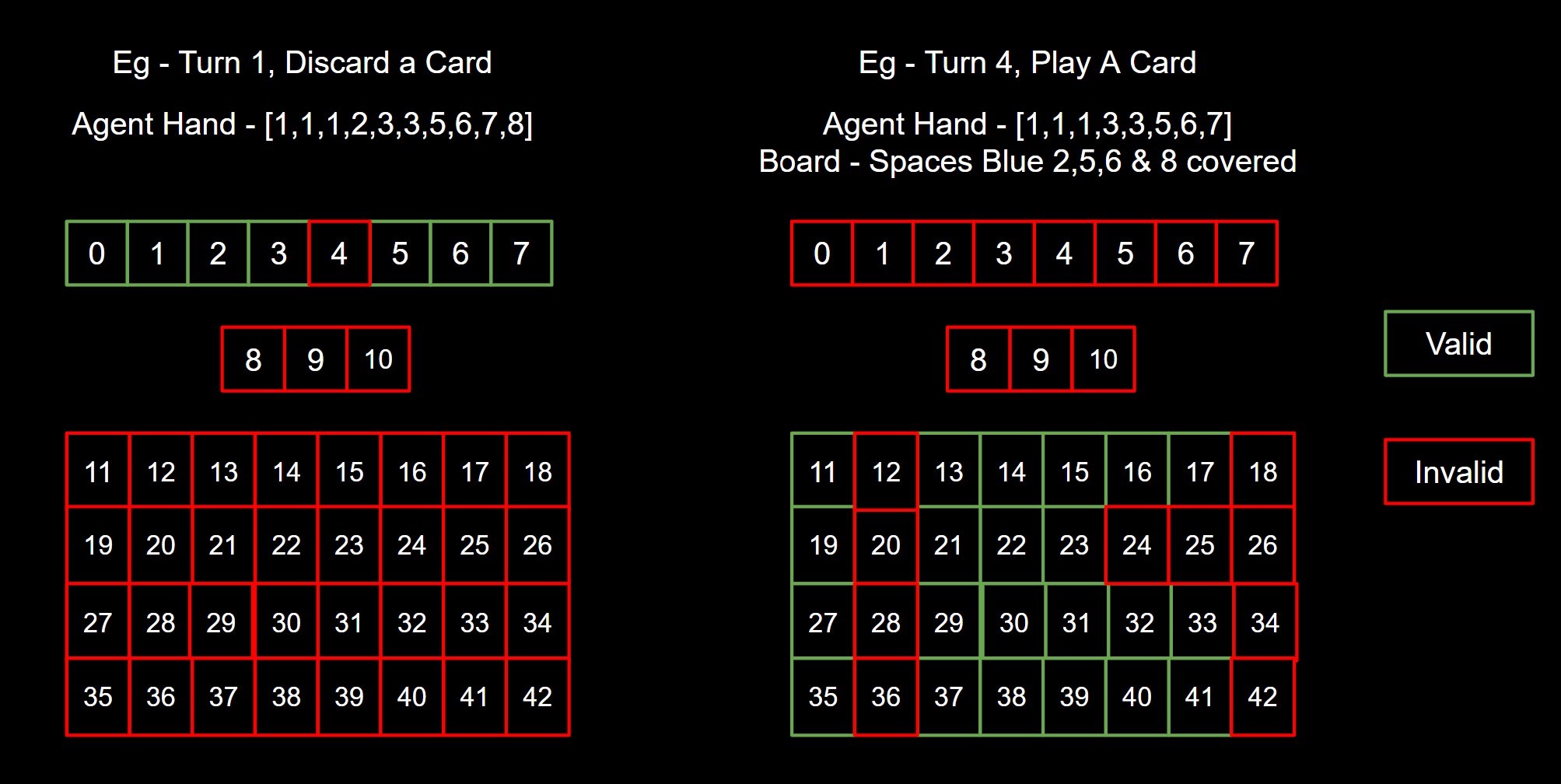
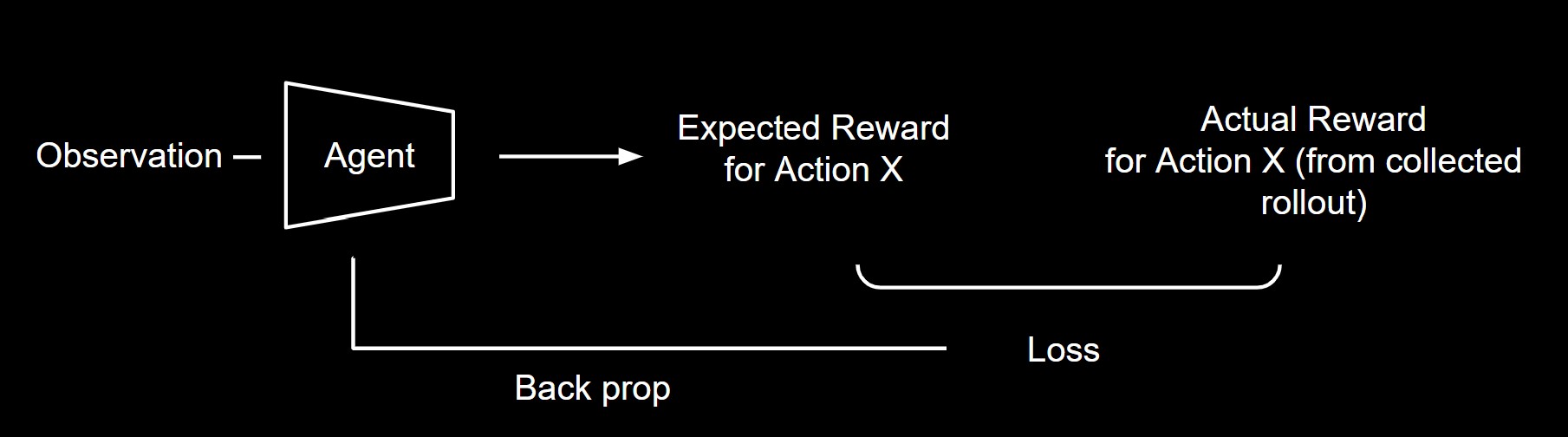
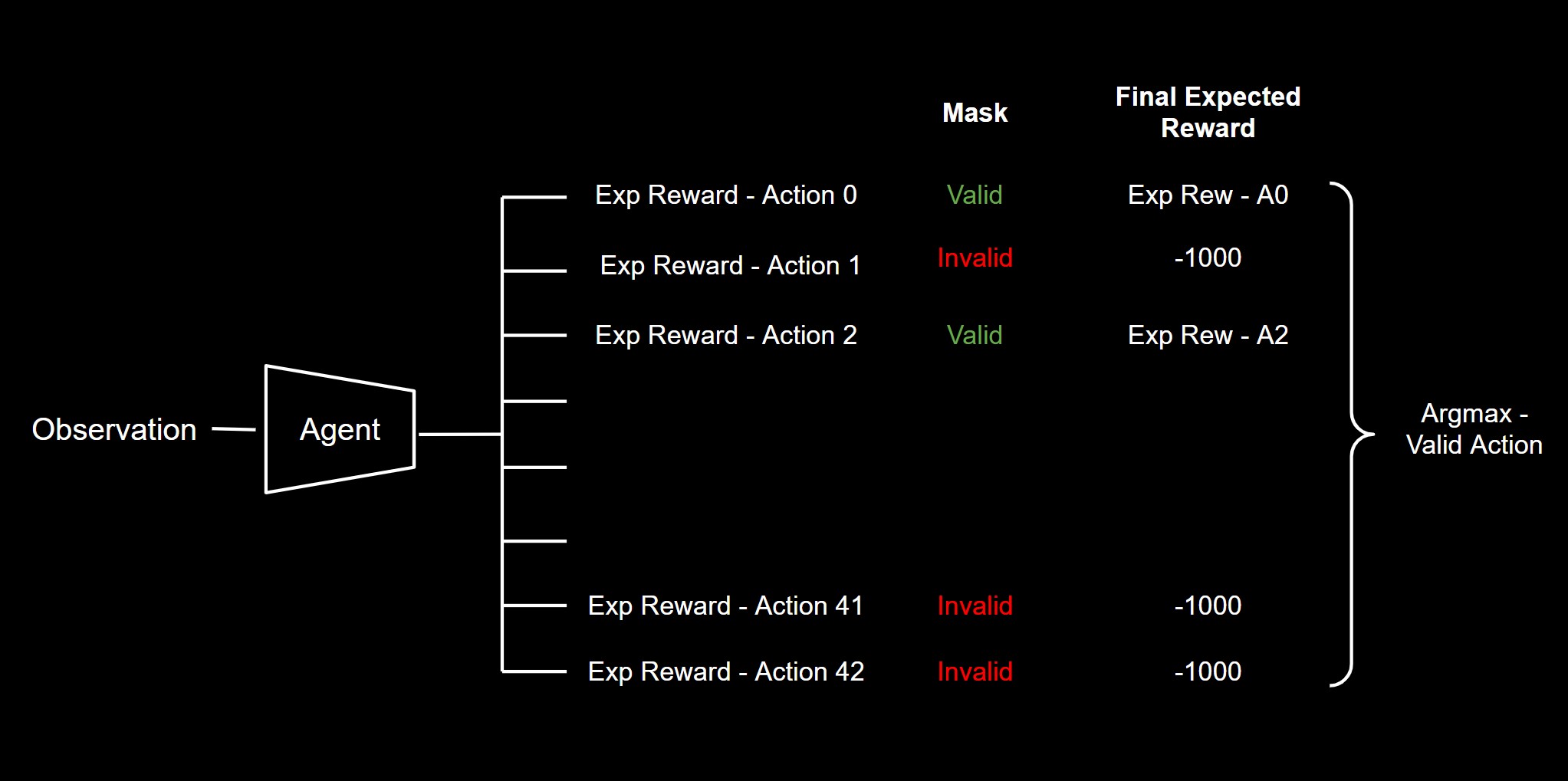
Now we would need to ensure our model does not predict these actions at all. To see how to achieve that we need to see how the predict function works. We know that our model predicts the “expected reward”, or “Q value”, when taking a particular action given an observation state. In order to select the next best action, the model then uses an argmax function to find the action with the maximum expected reward.
In an ideal way, when invalid actions are picked, the model learns that the reward is heavily negative and hence does not select that option in the future. However since certain actions are invalid only based on certain states and the magnitude of states is really really large, we saw the model struggle to learn the correct rules.
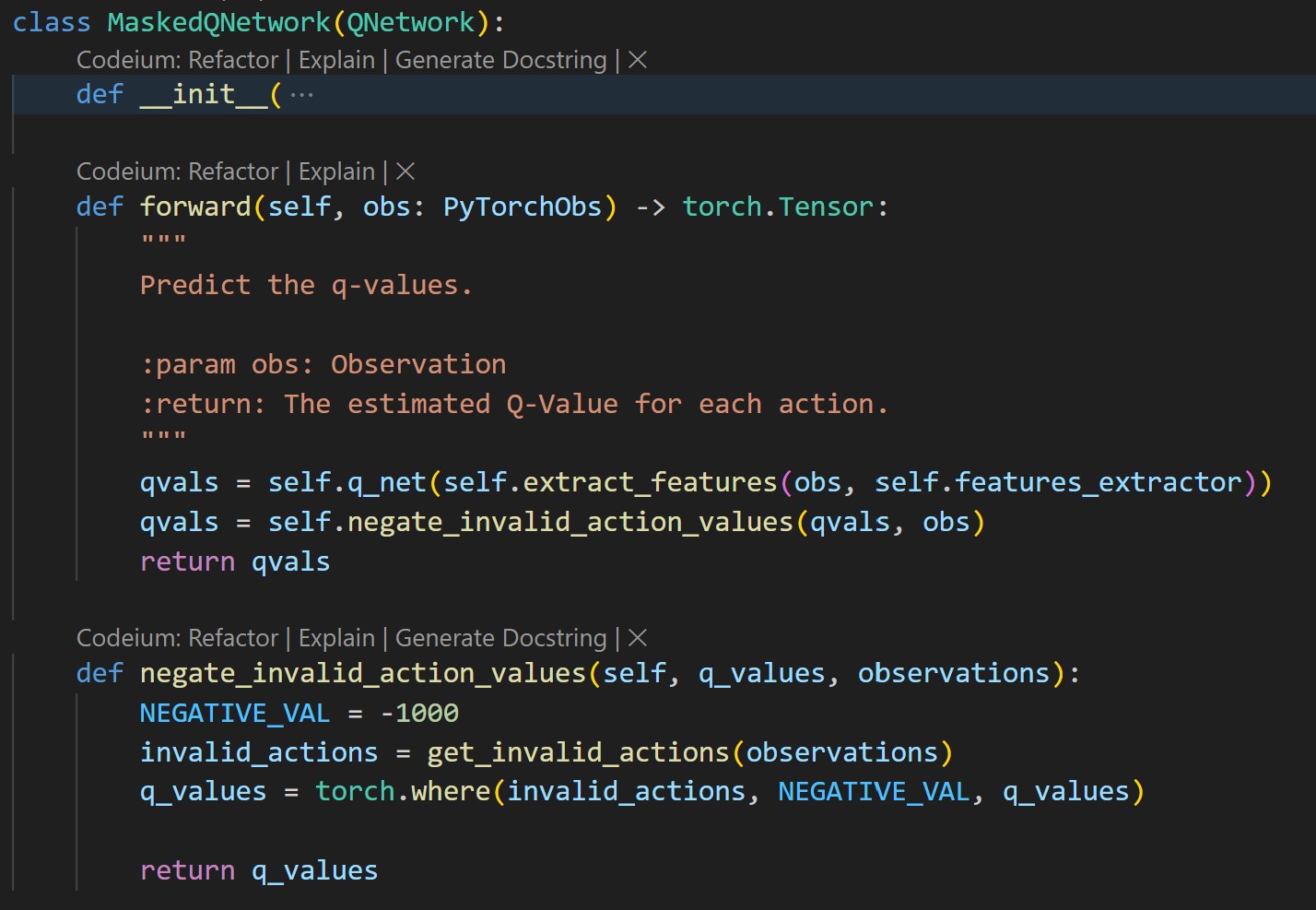
Hence what we want to do is to manually disallow those actions from being chosen. How? Given an observation, we can set the exepected rewards, or Q values, of those actions to a large negative value. Hence the argmax of all the expected rewards will never include the invalid actions.
I did this by updated the ‘_predict’ function in Q Network MLP by inheriting the base Q Network class and overriding the predict function.
I used the same masking when choosing a random action during exploration as well. Hence the model would always choose a valid action at any given stage.
Masked Training
Given the masking, the model would only select valid actions which means the game would ALWAYS be played till completion. Hence, the model was able to receive positive rewards as it would be able to play till the end of the game. In this case, the model could focus on maximizing the best positive reward from the get go, rather than struggling to understand all the possible or impossible moves and learning a huge set of negative rewards for invalid actions.
The episode mean hence jumped up to 8/9 (game can end in 9 turns or in some cases before that as well) and the mean was able to increase from negative (playing cards in such a way to block itself out from playing it’s remaining cards and hence getting a negative reward) to a positive score.
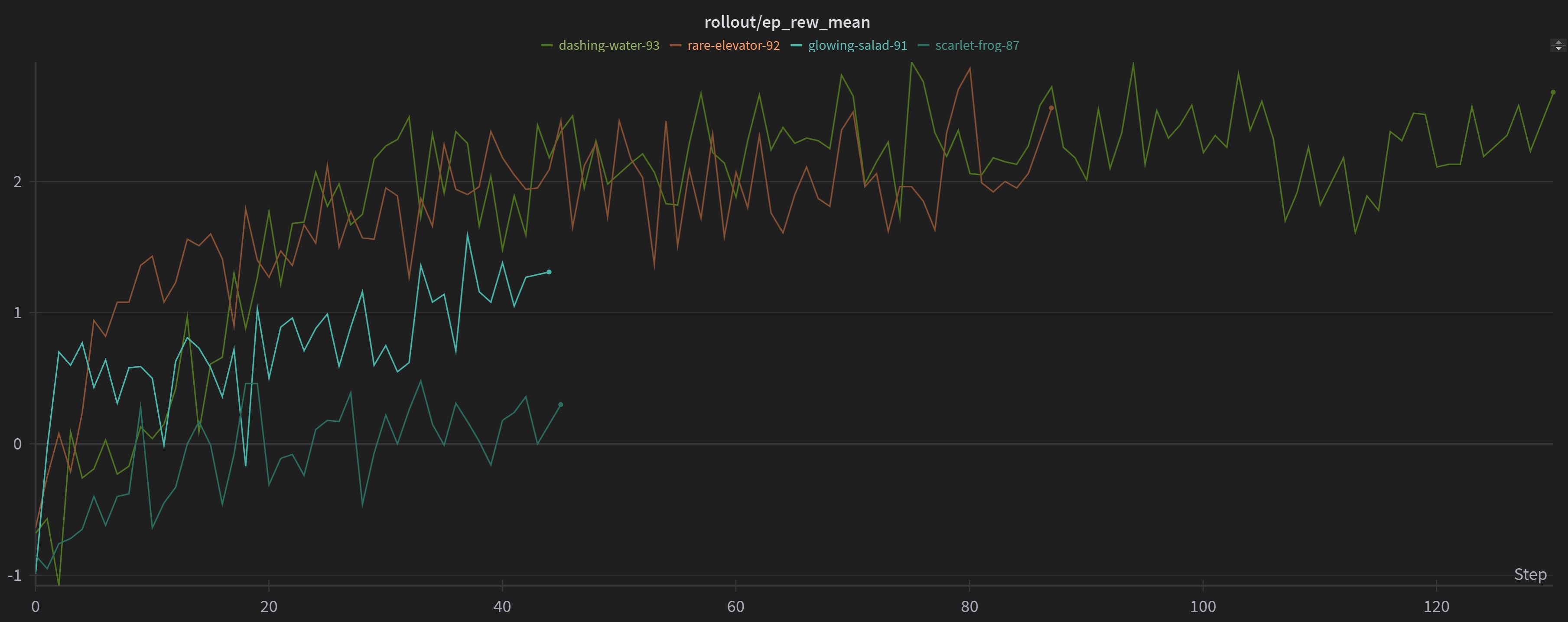
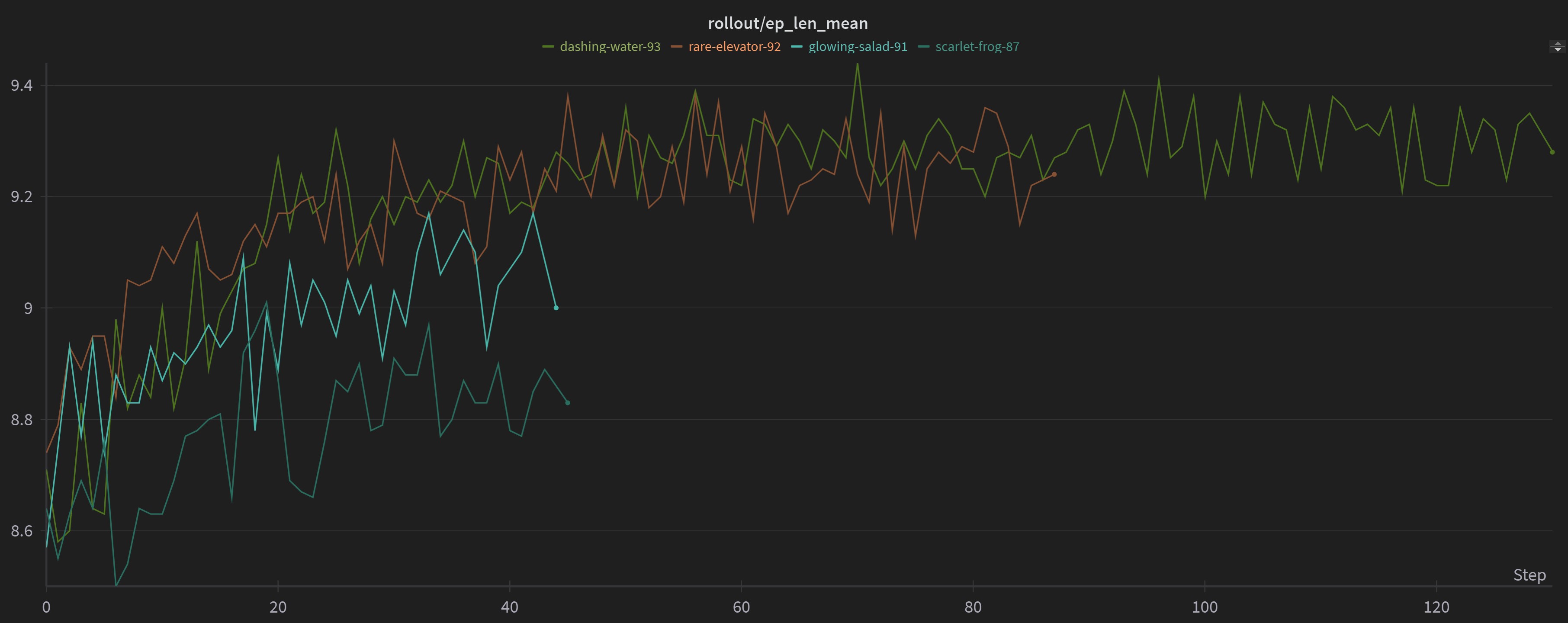
The model was able to reach an average mean reward of more than 2. Meaning that in every 1000 games, it was able to score and average of greater than 2. While there is still scope for improvement, being able to succesffuly play the game without blocking itself out and scoring a positive value is pretty incredible!!
Analysis
To analyze the results and check the performance of the model, I wrote a script to make it play a 1000 games and plotted a histogram of its achieved rewards.
In general, the mean being greater than 2, the model was able to achieve a positive reward for most of the games. However the histogram did not look as expected.
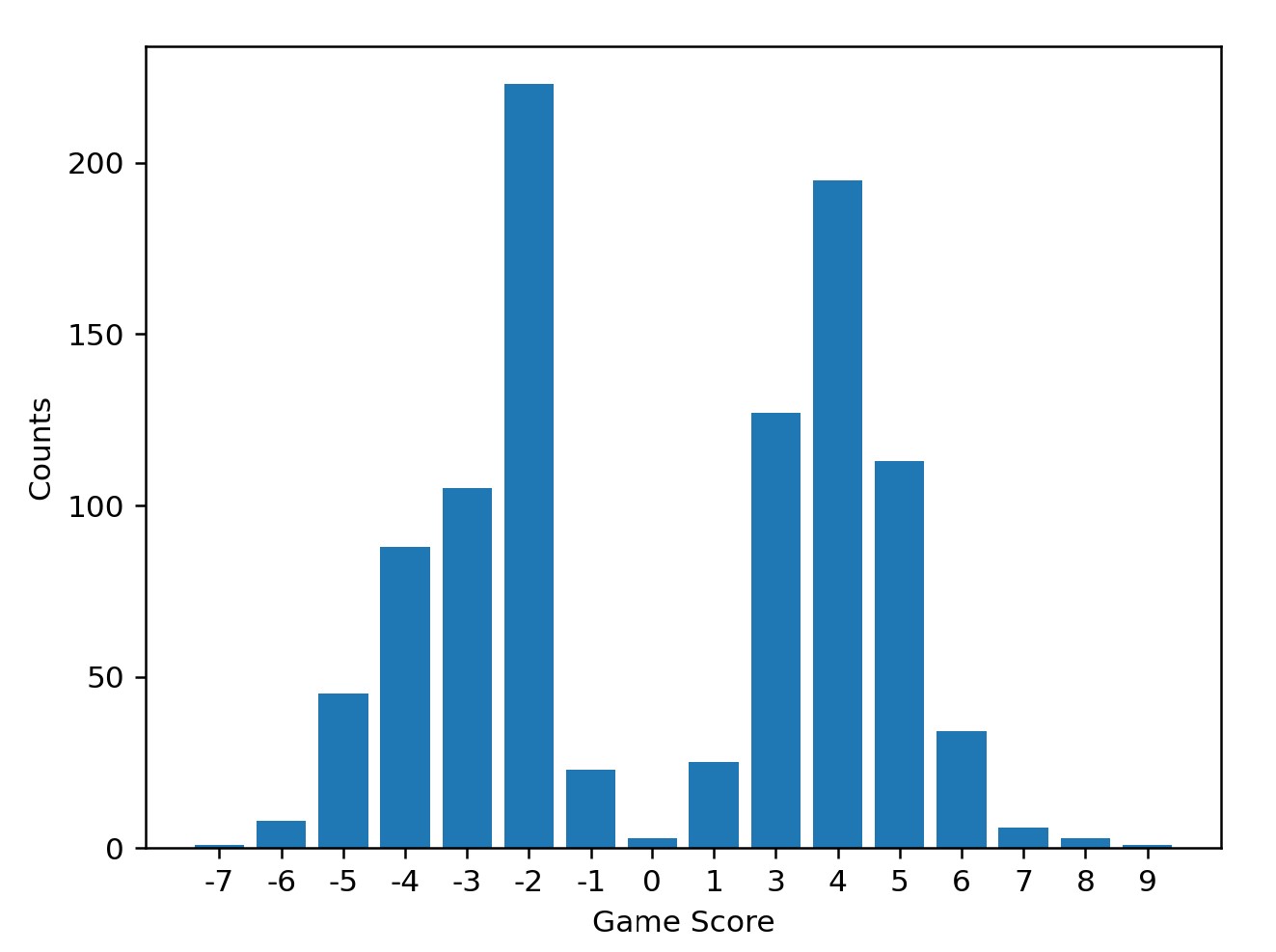
While the model had learned how to play, it had taken a very High Risk, High Reward approach. That means that it would play high cards to ensure it got points. If by chance it got blocked in, then it would fail and get high negative. However looking at the output and mean reward, it looks like this strategy overall was able to make the model score positive in general.
This is because it was playing against my partial strategy bots which wouldn’t force the agent into a corner and force it to get negative points. This is still something that needs to be fixed. Most likely by giving a higher negative reward in case the agent is unable to play cards and causes a break.
Self Play
The next step of training was to make the model play against smarter opponents. Since I couldnt sit and play 100 thousands of games as 3 different players against the computer (or get my friends to do so), the next step was to make the agent play against itself.
Hence I changed the code to have the environment set up with 3 other copies of the model that would just predict actions and would not learn. The observation was always set that it showed the details of the model that was going to take the action.
However since all the agents took the high risk high reward strategy, generally 1 out of the 4 would always be unable to play and break the game before the end allowing the other 3 players who also took high risks to get away with it. The mean reward increased in the training to 3+ as the risk ended up paying up a bit more often that the previous case.
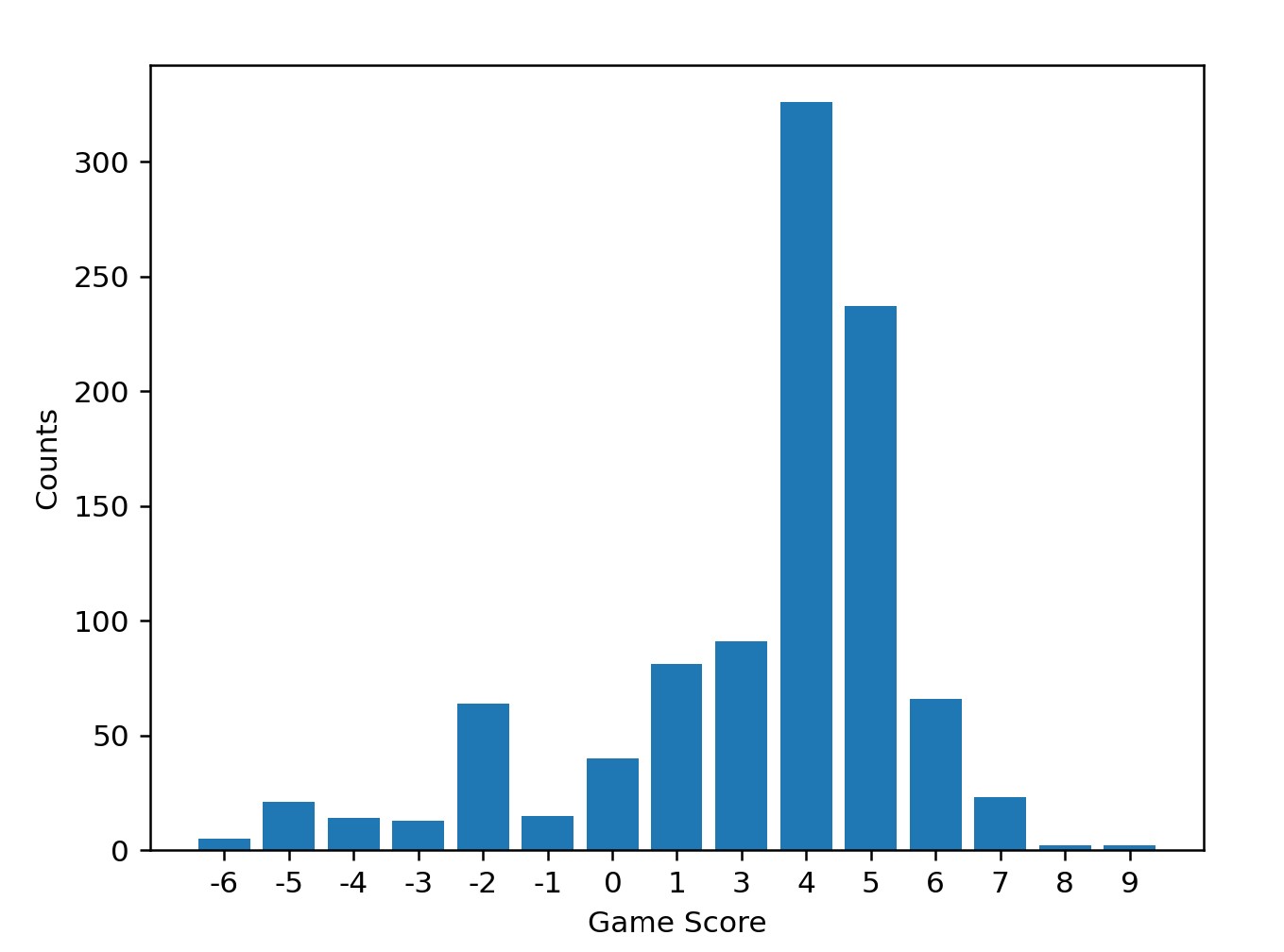
The model however does have to take slightly different actions, as all its opponents play aggressive and it does change a bit in play style. However I feel this would still overall not be able to beat 3 other humans consistently and needs some more tweaking.
SLOWDOW:
Since each agent player had to play its action after the previous action was played, the predict function had to be called sequentially instead of being called in a batched manner. Also since now all 4 players used a model to predict action, there was a 4x increase in the number of MLP calls and invalid action negation. This lead to a 5-10x slowdown of the training overall. Using a profiler (cProfile) I found that a majority of the slowdown was introduced in the prediction action of the new agent players which in itself mainly comprised of 80% of the forward call of the network and 20% of the invalid action calculation. This is still yet to be addressed.