My love for programming / boardgames / puzzles stems from my love for logic and deduction. Which is why doing Escape Rooms is just up my alley! Last year I found out about the podcast ‘Escape This Podcast’ hosted by the amazing Bill and Dani! If you haven’t checked it out and you like this sort of stuff, I 100% recommend them!
Bill and Dani basically run ‘Audio Escape Rooms’ where they design the script for an escape room and have contestants come and play it. Something like a RPG campaign, where instead of trying to level up and beat monsters, you solve puzzles in order to ‘escape’ the scenario.
AI as a Game Master (GM)
If you want to play it yourself with friends and family, they also release the full script of the rooms - for FREE! - for you to run. Now while I have a lot of friends who love this sort of stuff, not many would like to take the time to read through the script and run it for others (that and I havent asked them :P).
So… why not have an LLM run it for me?! It can read the script, it can answer questions and provide freidnly banter! It should work for sure right?!?!
Agentic Setup with LangGraph and OpenAI
To test this out I’m using LangChain and LangGraph to setup an agent to help be the Puzzle GM or Game Master.
I’m using ChatGPT (4o-mini) as the llm model to run the room.
And for the room I’m using the room Water you Solving one of their later rooms at the time of writing this. It’s got a mix of puzzles that are more word based and shouldn’t be too hard for an LLM to run.
The script for the room is a PDF detailing the introduction, all the observable locations / items the player can see and discover, a list of actions they can perform, the conclusion as well as some friendly notes to people running the rooms explaining the puzzles.
I setup an LangGraph agent with memory for the task. As an initial prompt, I passed the entire script through along with intructions on how to act, how to read the sections in the script, when to give hints and other points I noticed during running the room.
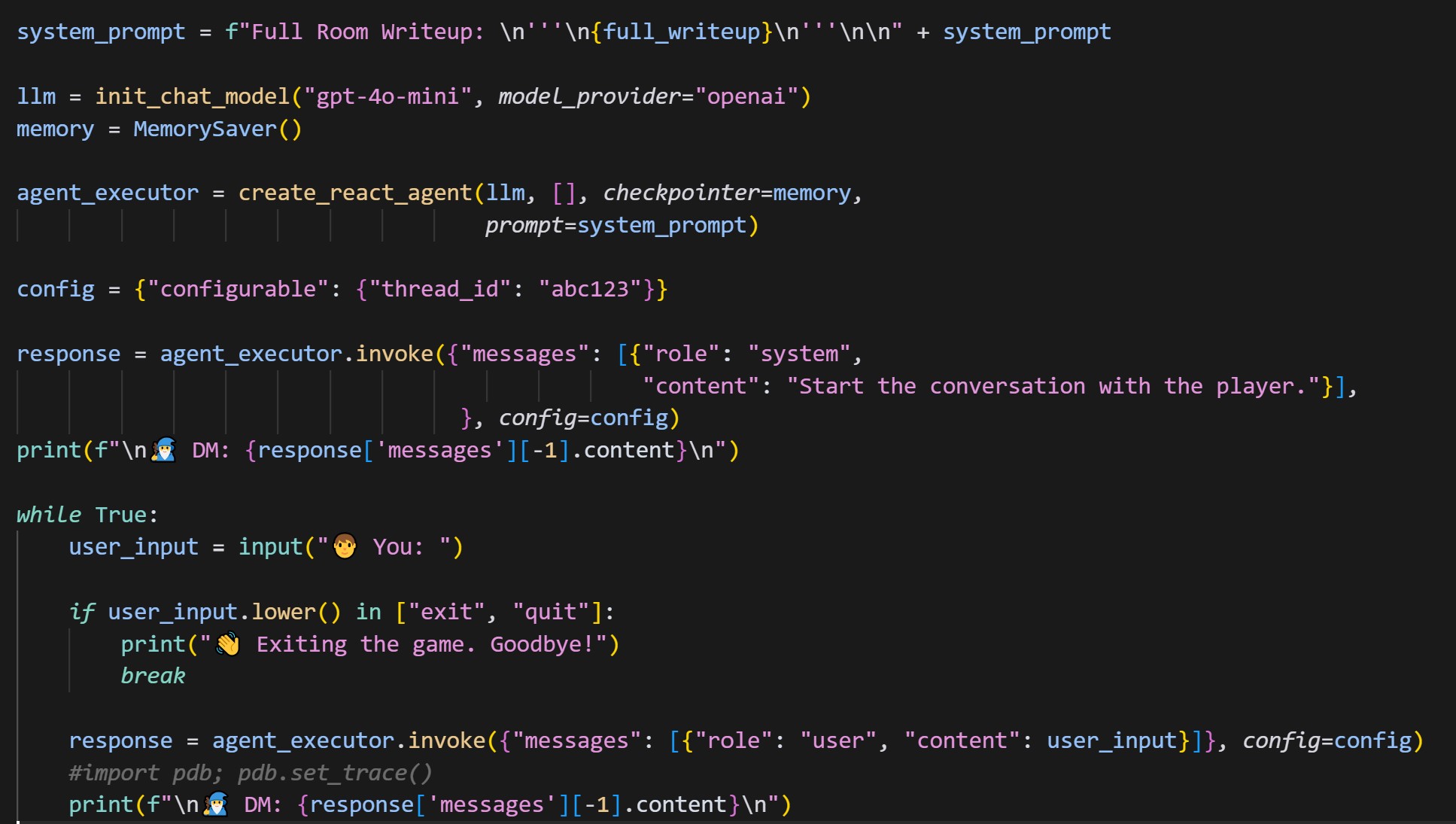
Post which there is a loop to get user input, pass it through to the LLM, get the response and pass it on to the user until the end. Most of these calls are just direct LLM calls, and hence do not use the Agentic capabilities much, but I have tried to incorporate some tools and states to help.
Agentic / LLM Shortcomings
So with all the excitement in the world I ran the code and hoped to be able to play the room successfully, meaning I could run other rooms I hadn’t played as well!
But I ran into a number of problems. Here are some of the key issues I observed and some workarounds. Do note, this has a bit of spoilers for the room, so if you actually like to try the room out yourself, be warned!
Unable to correctly track past actions
There were times that the LLM is not able to process what is already done by the human versur what is in the writeup. This leads to it incorrectly calculating conditional statements in the writeup, giving clues about future areas or allowing actions that shouldnt be allowed.
Incorrect Coniditional
For example, In this scenario, the user needs to get a bracelet to score points. Without it they should not be able to score points.
This is the line in the writeup about a particular action the user can take - “Relaxy River - riding the ride: You grab a donut …… you get out. [If you have the bracelet.] You get the attendant to scan one Cool Point onto your bracelet.”
However the LLM does not seem to adhere to the condition always:

This is fairly replicable. While the LLM model does sometimes mention that without a bracelet I cannot recieve points, many a times it fails.
Providing unexplored context
Sometimes to solve a puzzle you need to have all the pieces, which you get by exploring the space first. Here the LLM provides clues from areas that you have not observed.
Example, you need the bracelet right? If you clarify about it in the start, it mentions that you cannot get one from the Kiosk even though you have not been to the kiosk yet :(

The LLM provides context that is yet to be explored, and this can spoil a lot of the fun.
Custom states
LangGraph provides the ability to provide custom ‘states’ or sets of values that the agent can use to track. Hence it is possible to have the inventory marked in the state which the agent can use before checking conditionals such as ‘If you have the bracelet’.
I’ve yet to try this out successfully, but it starts to feel specific for the given room, while I want a more general solution.
Highly Specific Prompt Requirements
This is a general point of LLMs which is why the role of ‘Prompt Engineer’ even exists. The intial system prompt started simple but started to grow more complex in order to handle different behaviours shown by the LLM. Some of my additions still do not necessarily work.
Here is another example - hints about what to do next. As a person playing the puzzle, you do not want hints until you need them. However the LLM is quick to provide hints about next steps.
Now in this case, you need to find a bracelet to get points. The aim is to go explore around and luck across it, but if you even discuss about it, the LLM quickyl decides to tell you how to get it :(

I’ve tried adding the line “Do not provide hints to the player unless they specifically ask for them.” but that is not enough. There are many cases like this where the initial prompt starts to become complex.
Math is Hard
Math is hard for you and me, but it’s especially hard for ChatGPT
This scenario involves some math in the puzzles. You have points you need to collect, words to count as well as a puzzle with a number pattern. In these cases the LLM model is unable to do the math correctly.
To get the bracelet, you need to solve a number pattern puzzle that is generated dynamically by the Game Master. Which means the LLM needs to generate the number pattern by adding or subtracting some digits. The LLM is unable to do this properly.

- First, you get pushed back only if wave comes before the time you've swam. Here I swam for 4s (4 * 1m/s) and the wave came at 5s, but I got 'pushed back'.
- Even though I got 'pushed back', I somehow ended up 16 meters from the start! It somehow moved me to 4 meters from the end, rather than 4 meters from the start.
It struggles with math like this.
Math Tool
I believe some of the math can be helped solved by providing a ‘calculator’ tool to the agent which can help solving addition/subtraction issues. However it cannot help make the model understand when exactly to push the player back and so on.
Pictures in puzzles
A lot of the puzzles provide puzzles in picture form. While this scenario I feel is not too picture heavy, a lot of the other puzzle rooms can have a strong dependence on pictures which would need some additional multi modal processing.
Conclusion
An LLM is certainly on the track to being able to run these rooms, but just not there yet. While additional prompts, edits to the writeup, and specific states and tools may work to complete this scenario, it becomes too specific and cannot work as a general solution for all the rooms.
Better analytical / logical reasoning by the engines is definetly required before it can become a trustable agent. For now I’ll just have to enjoy listening to the podcast / running the rooms for my friends!